How it works?
Fully explaining how YDB works in detail takes quite a while. Below you can review several key highlights and then continue exploring documentation to learn more.
YDB architecture
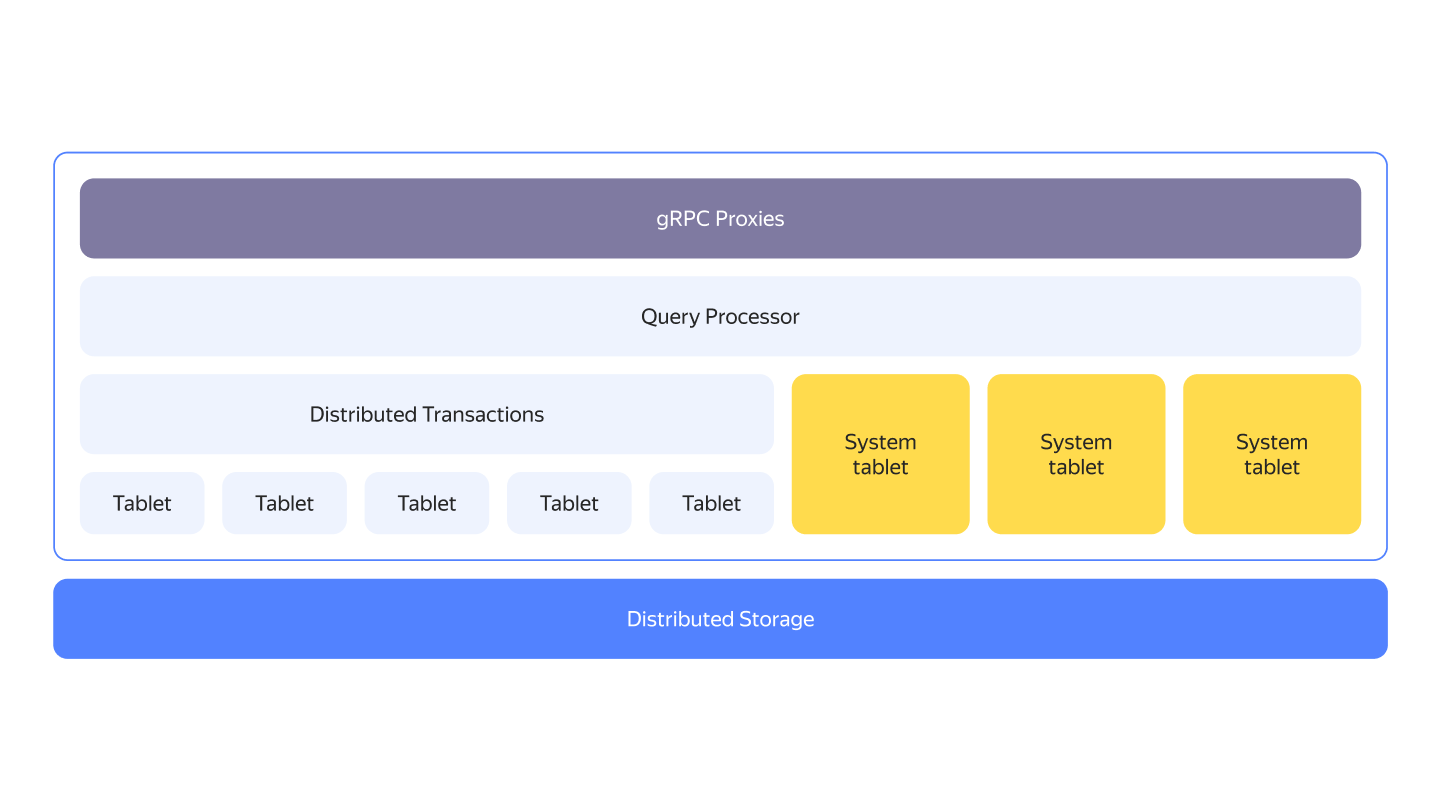
YDB clusters typically run on commodity hardware with shared-nothing architecture. If you look at YDB from a bird's eye view, you'll see a layered architecture. The compute and storage layers are disaggregated, they can either run on separate sets of nodes or be co-located.
One of the key building blocks of YDB's compute layer is called a tablet. They are stateful logical components implementing various aspects of YDB.
The next level of detail of overall YDB architecture is explained in the General YDB schema article.
Hierarchy
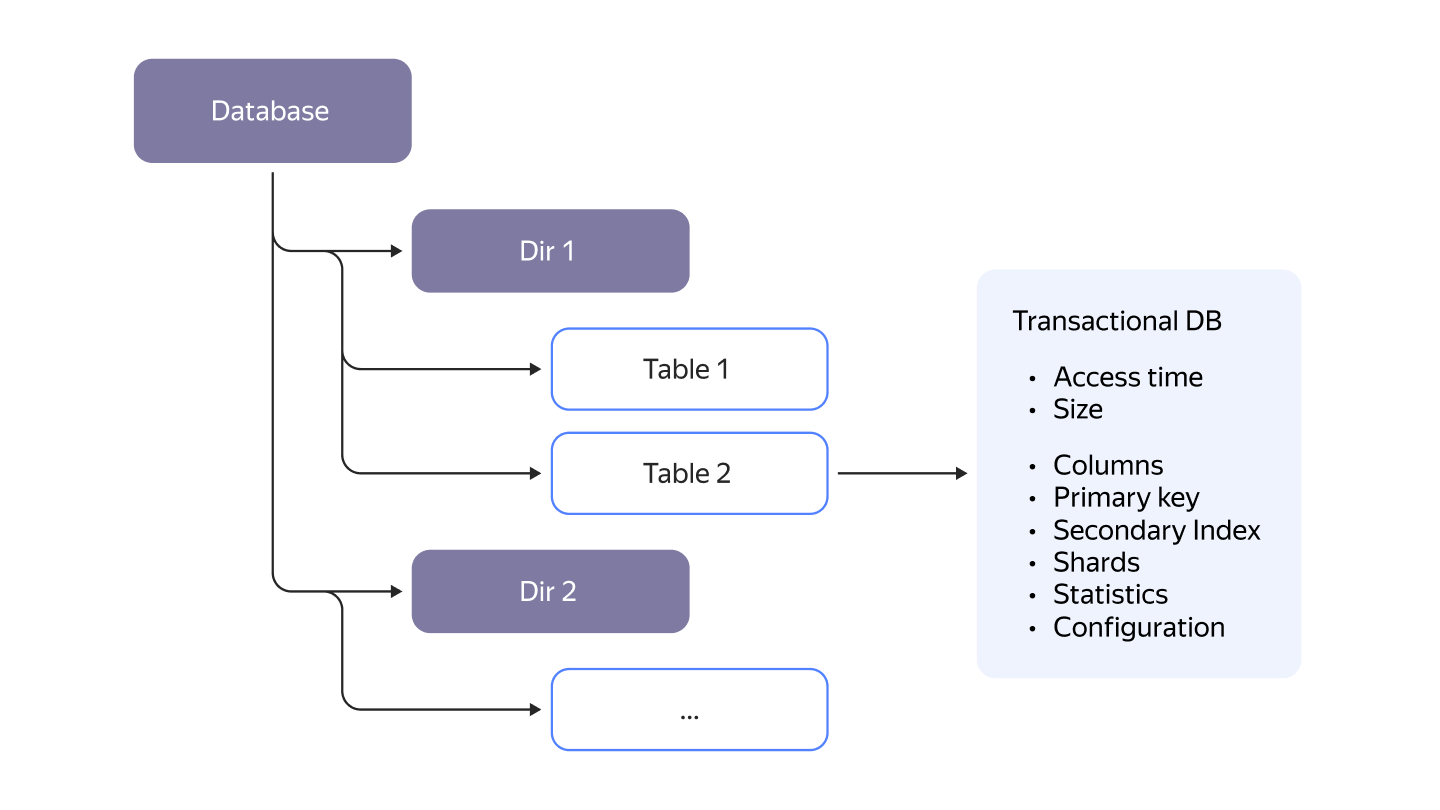
From the user's perspective, everything inside YDB is organized in a hierarchical structure using directories. It can have arbitrary depth depending on how you choose to organize your data and projects. Even though YDB does not have a fixed hierarchy depth like in other SQL implementations, it will still feel familiar as this is exactly how any virtual filesystem looks like.
Table
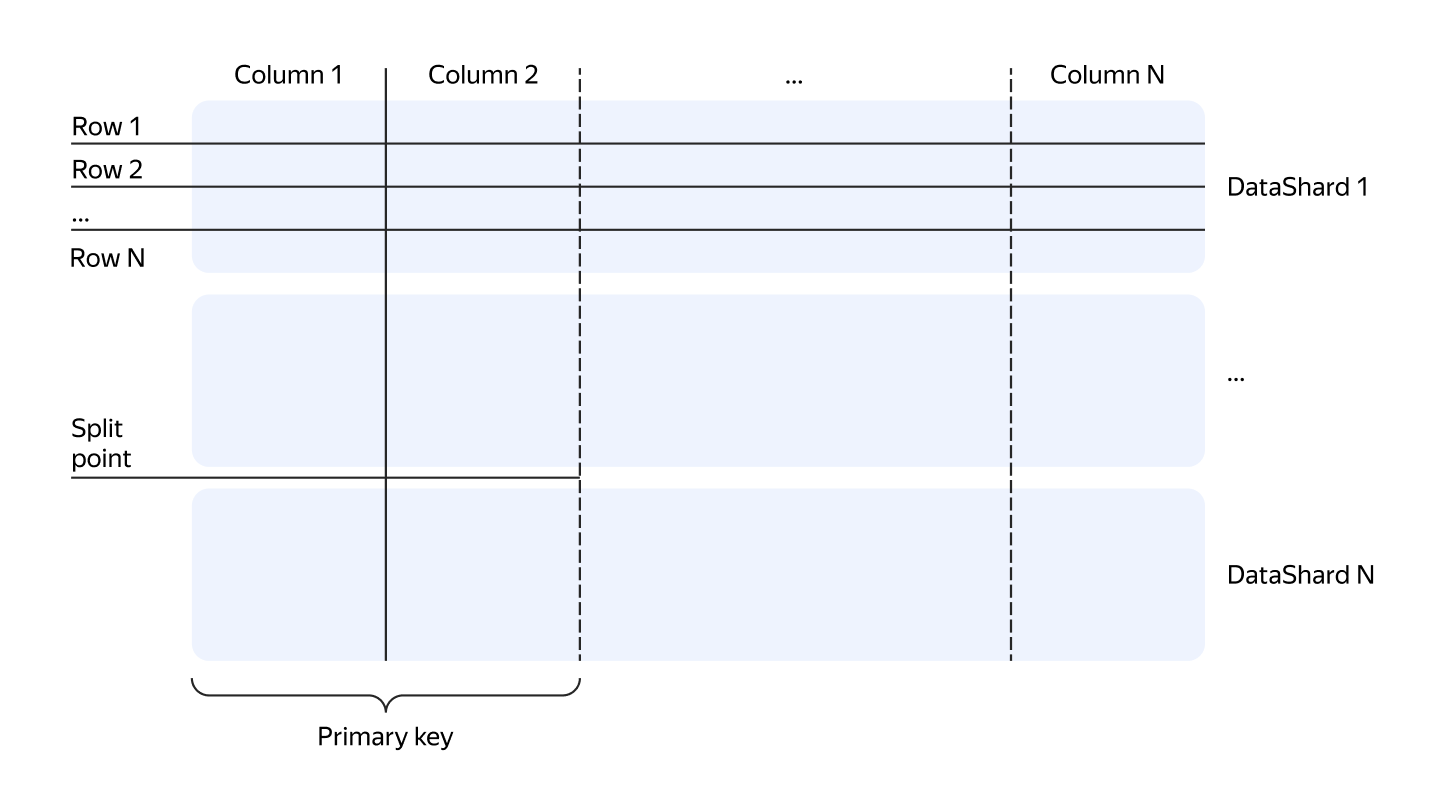
YDB provides users with a well-known abstraction — tables. In YDB, there are two main types of tables:
- Row-oriented tables are designed for OLTP workloads.
- Column-oriented tables are designed for OLAP workloads.
Logically, from the user’s perspective, both types of tables look the same. The main difference between row-oriented and column-oriented tables lies in how the data is physically stored. In row-oriented tables, the values of all columns in each row are stored together. In contrast, in column-oriented tables, each column is stored separately, meaning that cells from different rows are stored next to each other within the same column.
Regardless of the type, each table must have a primary key. Column-oriented tables can only have NOT NULL columns in primary keys. Table data is physically sorted by the primary key.
Partitioning works differently in row-oriented and column-oriented tables:
- Row-oriented tables are automatically partitioned by primary key ranges, depending on the data volume.
- Column-oriented tables are partitioned by the hash of the partitioning columns.
Each partition of a table is processed by a specific tablet, called a data shard for row-oriented tables and a column shard for column-oriented tables.
Split by load

Data shards will automatically split into more ones as the load increases. They automatically merge back to the appropriate number when the peak load goes away.
Split by size
.png)
Data shards also will automatically split when the data size increases. They automatically merge back if enough data will be deleted.
Automatic balancing
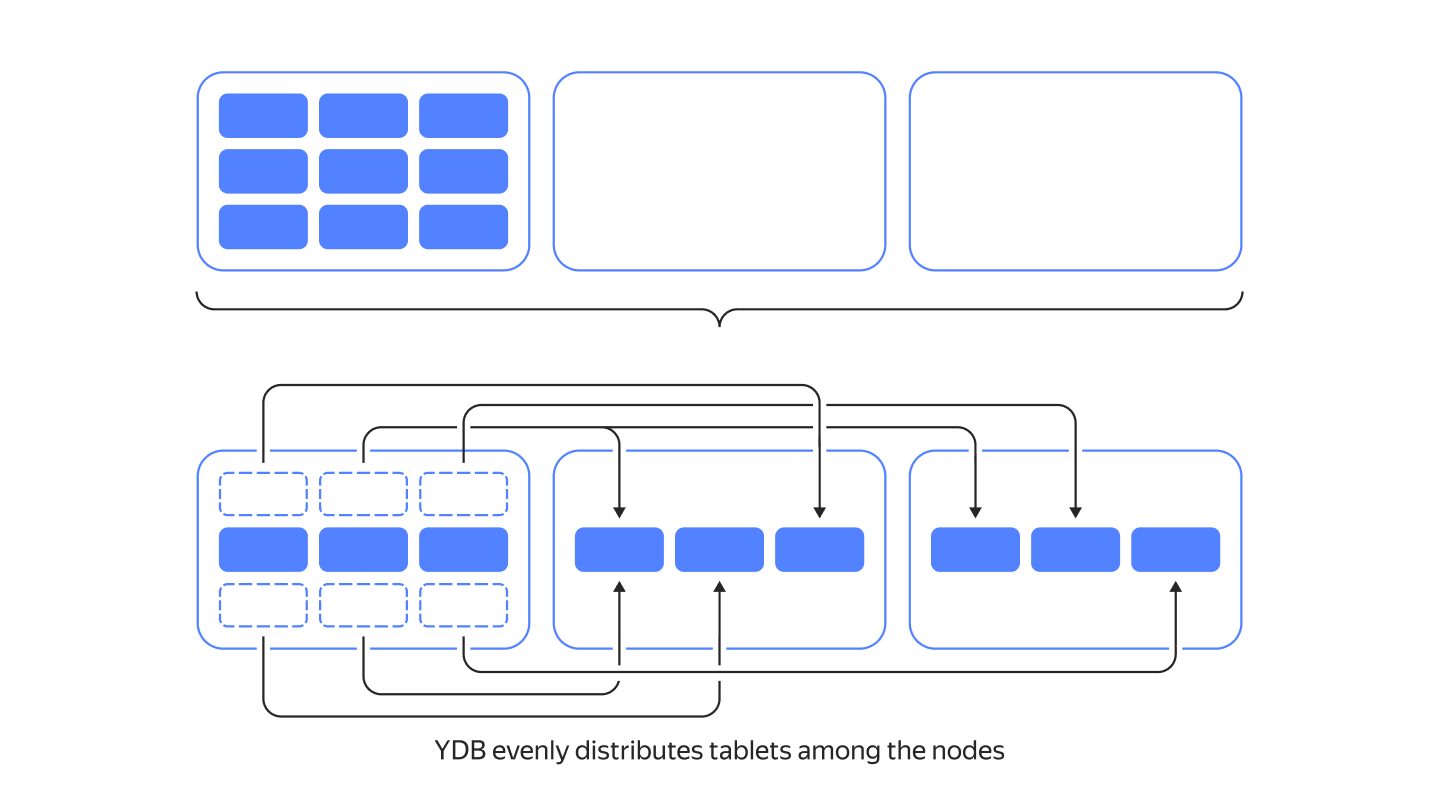
YDB evenly distributes tablets among available nodes. It moves heavily loaded tablets from overloaded nodes. CPU, Memory, and Network metrics are tracked to facilitate this.
Distributed Storage internals
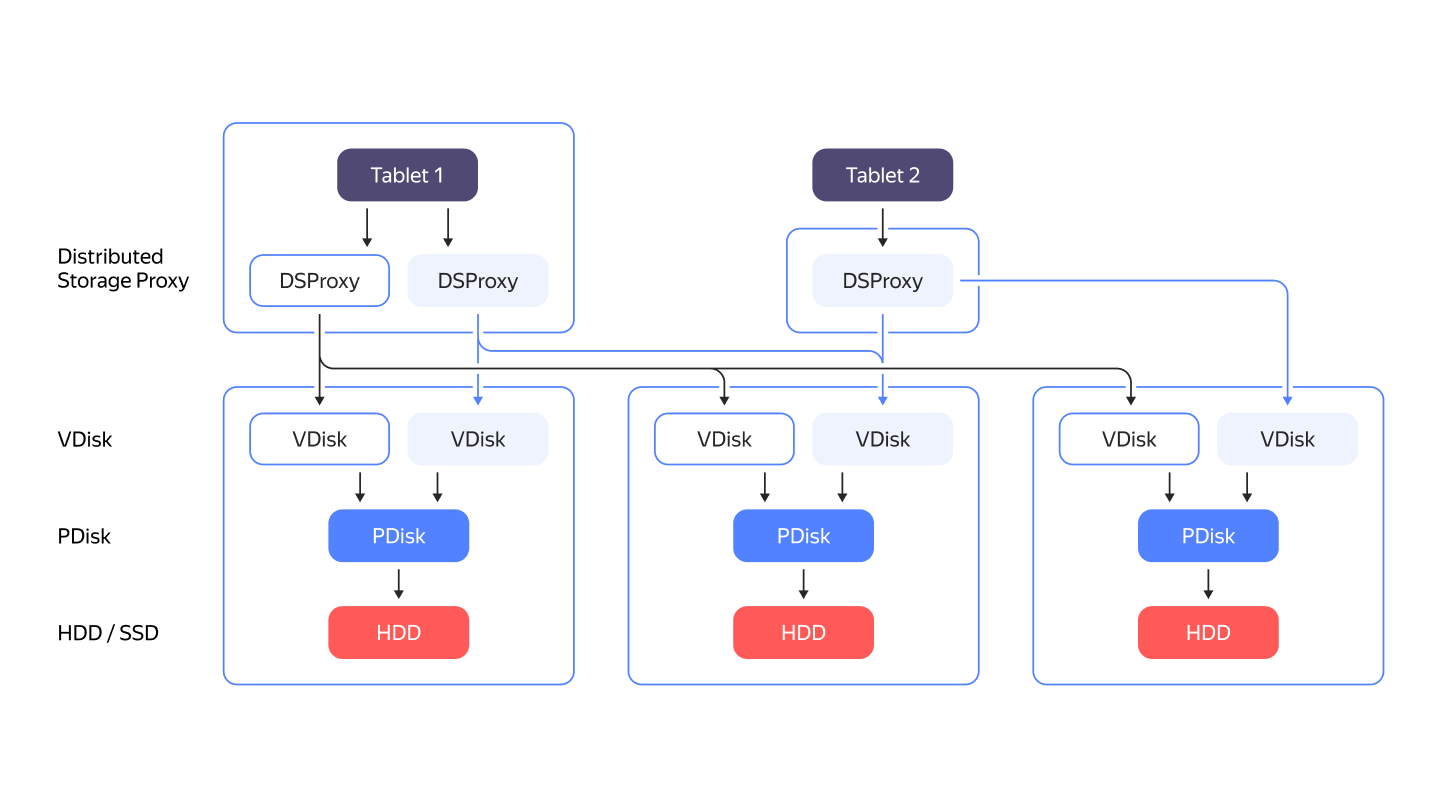
YDB doesn't rely on any third-party filesystem. It stores data by directly working with disk drives as block devices. All major disk kinds are supported: NVMe, SSD, or HDD. The PDisk component is responsible for working with a specific block device. The abstraction layer above PDisk is called VDisk. There is a special component called DSProxy between a tablet and VDisk. DSProxy analyzes disk availability and characteristics and chooses which disks will handle a request and which won't.
Distributed Storage proxy (DSProxy)
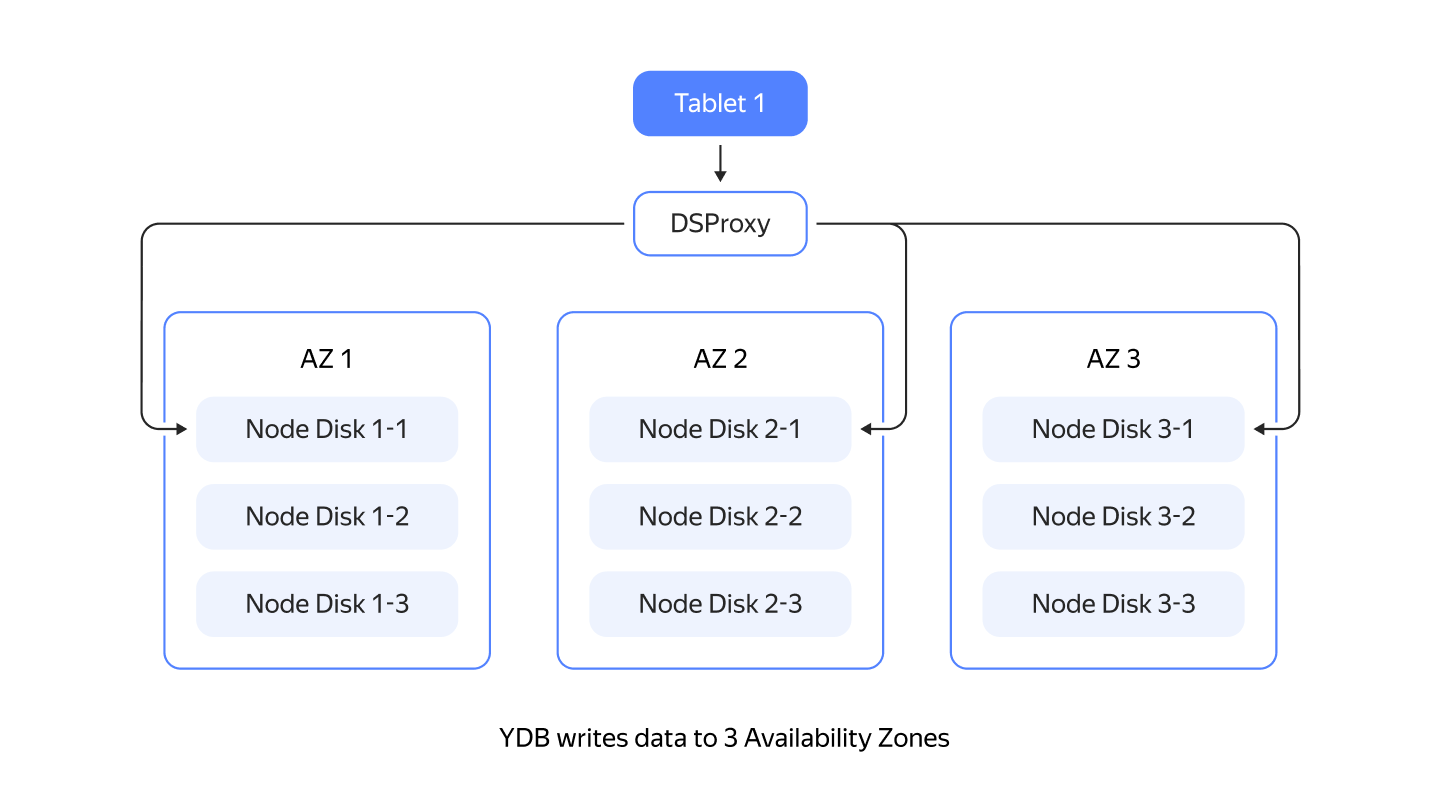
A common fault-tolerant setup of YDB spans 3 datacenters or availability zones (AZ). When YDB writes data to 3 AZ, it doesn’t send requests to obviously bad disks and continues to operate without interruption even if one AZ and a disk in another AZ are lost.